
자바에서 데이터를 다루는 컬렉션(Collection)은 세 가지 축으로 구성된다: List, Set, Map. 이 중 Map은 가장 실용적이고 많이 쓰이지만, 동시에 가장 오해가 많은 컬렉션이기도 하다.
많은 개발자들이 Map을 단순히 "키-값 저장소" 정도로 인식하고 사용하지만, 내부 구조나 구현 방식에 대한 이해 없이 사용하면, 중복 저장, 순서 오류, 정렬 실패 등 의도치 않은 결과를 마주하게 된다. 특히 Set을 학습한 사람이라면 "Set은 고유한 값만 저장하는데, Map은 키가 Set처럼 동작하고, 값이 하나 더 붙은 형태구나"라고 이해하면 비교적 쉽게 접근할 수 있다.
이번 글에서는 Map이 어떤 구조로 동작하며, 왜 Entry라는 개념이 필요한지, 그리고 대표적인 구현체인 HashMap, LinkedHashMap, TreeMap은 어떤 차이를 가지는지를 알아보자
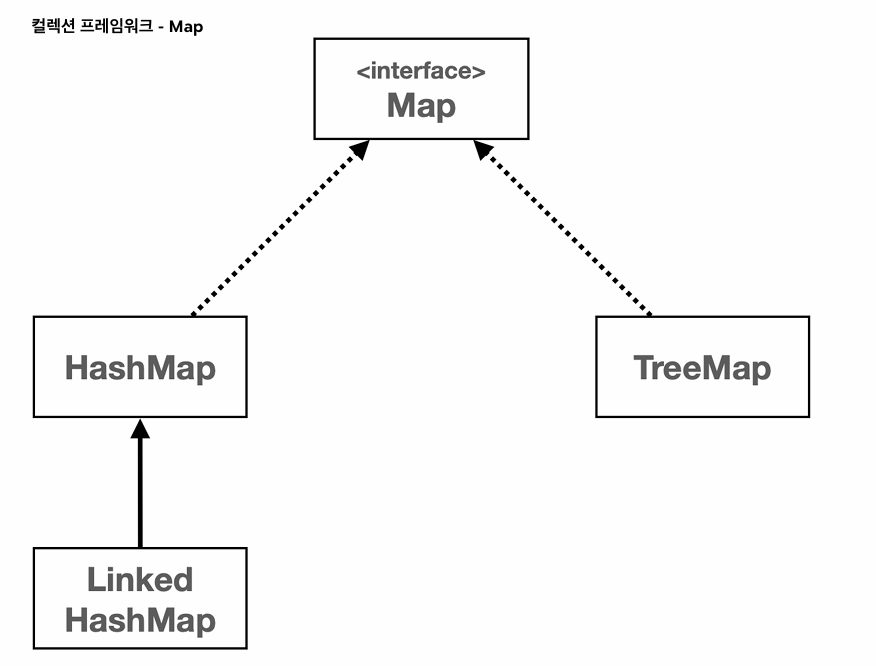
1. Map은 Set의 확장 개념이다
자바에서 Map은 하나의 키에 하나의 값을 연결하여 저장하는 자료구조다. Set이 중복 없는 데이터를 저장한다면, Map은 중복 없는 Key와 그에 대응되는 Value를 함께 저장한다.
사실 Set은 Map의 특수한 형태라고 볼 수 있다. 내부적으로 HashSet은 HashMap을 사용하여 key만 저장하고, value는 항상 동일한 상수(Object)로 채운다. 즉, Map이 Set보다 더 일반적인 구조이고, Set은 key만 쓰는 경량화된 버전이라고 보면 된다.
실제로 자바코드를 확인하면 아래와 같이 set은 map을 사용하는 것을 확인할 수 있다.
//자바에서 구현한 HashSet 코드 일부
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
@java.io.Serial
static final long serialVersionUID = -5024744406713321676L;
transient HashMap<E,Object> map; //맵사용
// Dummy value to associate with an Object in the backing Map
static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing {@code HashMap} instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
2. Map은 키와 값을 묶는 구조다 – Entry
Map은 내부에서 Key-Value 쌍을 Entry라는 객체로 묶어 저장한다. 이 Entry는 Map.Entry<K, V>라는 인터페이스로 정의되어 있으며, 하나의 키와 하나의 값을 하나의 묶음으로 관리한다.
즉, 우리가 map.put("name", "홍길동")처럼 데이터를 저장하면, 자바 내부에서는 "name"을 키로 하고 "홍길동"을 값으로 하는 Entry 객체를 만들어 해시 테이블에 보관한다. 하나의 Map에는 이런 Entry 객체가 여러 개 저장되며, 각 Entry는 고유한 키를 가진다.
3. Map의 주요 기능과 메서드
Map 인터페이스는 다양한 기능을 제공한다. 그중 자주 사용되는 메서드는 다음과 같다:
- put(key, value) : 키와 값을 저장한다. 같은 키가 이미 있으면 값을 덮어쓴다.
- putIfAbsent(key, value) : 키가 없을 때만 값을 저장한다.
- get(key) : 키에 대응되는 값을 가져온다.
- getOrDefault(key, defaultValue) : 키가 없으면 기본값을 반환한다.
- remove(key) : 해당 키의 항목을 제거한다.
- containsKey(key) / containsValue(value) : 특정 키나 값을 포함하고 있는지 확인
- clear() / isEmpty() / size() : 전체 초기화, 비어 있는지 확인, 크기 반환
- keySet() : 키들만 Set으로 반환
- values() : 값들만 Collection으로 반환
- entrySet() : Entry<K,V> 객체의 집합으로 반환
이 메서드들을 잘 활용하면 단순한 저장소 이상의 역할을 수행할 수 있다.
4. 자바의 대표적인 Map 구현체 3가지
자바에서는 Map 인터페이스를 구현한 다양한 클래스가 있다. 그중 가장 널리 쓰이는 세 가지는 HashMap, LinkedHashMap, TreeMap이다.
HashMap
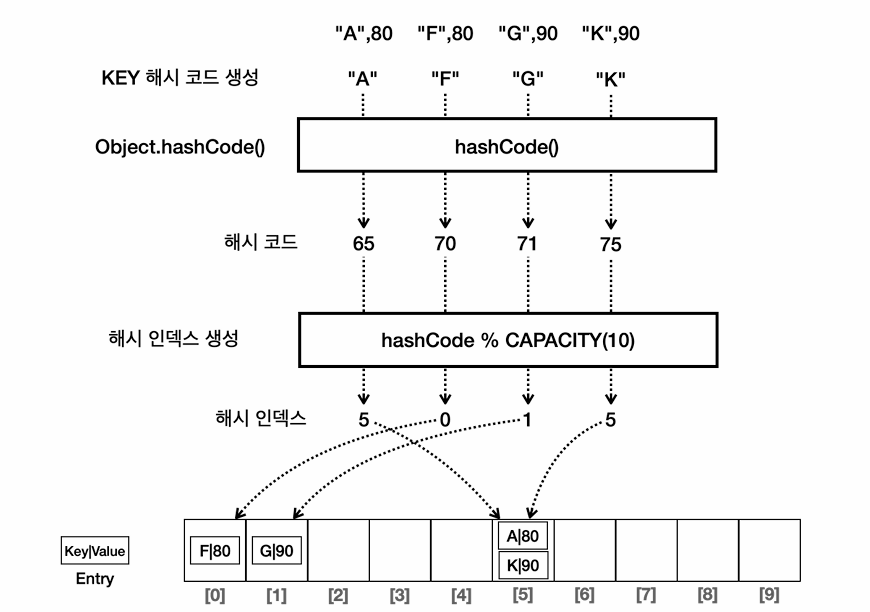
HashMap은 가장 기본적인 Map 구현체다. 내부적으로 해시 테이블을 사용하며, 키의 hashCode()를 기반으로 값을 저장하고 검색한다. 저장 순서는 전혀 보장되지 않는다. 하지만 평균적으로 put(), get() 등의 연산은 O(1)의 빠른 성능을 보장한다.
HashSet처럼 충돌이 발생할 경우 하나의 버킷에 여러 Entry가 저장되며, 자바 8부터는 일정 수 이상 충돌이 발생하면 내부 구조를 Tree로 전환해 성능을 유지한다.
LinkedHashMap
LinkedHashMap은 HashMap과 거의 동일하지만, 내부에 연결 리스트를 사용해 입력 순서를 유지한다. 즉, 데이터를 입력한 순서대로 반복하거나 출력할 수 있다. 캐시(Cache) 구현 시 자주 사용되며, LRU(Least Recently Used) 알고리즘 구현에도 쓰인다.
성능은 HashMap보다 약간 느릴 수 있으나, 삽입 순서가 중요한 경우에는 매우 유용하다.
TreeMap
TreeMap은 키를 자동으로 정렬하며 저장하는 Map이다. 내부적으로는 Red-Black Tree라는 이진 정렬 트리를 사용한다. 키에 Comparable이 구현되어 있거나, 생성 시 Comparator를 제공해야 한다. 삽입, 삭제, 검색은 모두 O(log n)의 시간 복잡도를 가진다.
정렬된 순서로 데이터를 처리하거나, 특정 범위에 해당하는 키만 조회할 필요가 있을 때 적합하다.
5. 실제 코드로 확인해보는 차이점
public class JavaMapMain {
public static void main(String[] args) {
run(new HashMap<>());
run(new LinkedHashMap<>());
run(new TreeMap<>());
}
private static void run(Map<String, Integer> map) {
System.out.println("map = " + map.getClass());
map.put("C", 10);
map.put("B", 20);
map.put("A", 30);
map.put("1", 40);
map.put("2", 50);
for (String key : map.keySet()) {
System.out.print(key + "=" + map.get(key) + " ");
}
System.out.println();
}
}실행 결과:
map = class java.util.HashMap
A=30 1=40 B=20 2=50 C=10 ← 순서 없음
map = class java.util.LinkedHashMap
C=10 B=20 A=30 1=40 2=50 ← 입력 순서 유지
map = class java.util.TreeMap
1=40 2=50 A=30 B=20 C=10 ← 키 기준 정렬
6. 실무에서 Map을 사용할 때 주의할 점
Map의 핵심은 키다. 따라서 Map에 키로 사용되는 객체는 반드시 hashCode()와 equals()를 올바르게 오버라이딩해야 한다. 그래야 같은 키를 기준으로 값이 덮어쓰여지고, 검색도 정확히 이루어진다.
이는 HashMap, LinkedHashMap에서 특히 중요하며, 잘못 구현된 equals()나 hashCode()는 중복된 키가 저장되거나, 존재하는 키를 찾지 못하는 문제를 발생시킨다.
또한, TreeMap을 사용할 경우에는 Comparable 또는 Comparator가 구현되어 있지 않으면 ClassCastException이 발생할 수 있으므로 주의해야 한다.
마무리하며
Map은 단순한 키-값 저장소가 아니다. 내부에서는 Entry라는 객체를 통해 키와 값이 결합되어 저장되고, 각 구현체는 목적에 따라 성능과 기능이 달라진다. 정렬이 필요하면 TreeMap, 순서 유지가 중요하면 LinkedHashMap, 빠른 접근이 목적이라면 HashMap을 선택하면 된다.
그리고 무엇보다 중요한 것은 키로 사용되는 객체의 equals()와 hashCode()를 반드시 정확히 구현해야 한다는 점이다. Set과 마찬가지로, 해시 기반 자료구조는 이 두 메서드를 기준으로 동작하며, 이들이 잘못 구현되어 있을 경우, 어떤 Map 구현체를 사용하든 기대한 결과를 얻지 못할 수 있다.
감사합니다.
'자바' 카테고리의 다른 글
| [JAVA] Comparable과 Comparator에 대하여 (3) | 2025.07.20 |
|---|---|
| [JAVA] 자바의 Iterable과 Iterator (0) | 2025.07.20 |
| [JAVA] Set 인터페이스에 대하여 (3) (1) | 2025.07.20 |
| [JAVA] List에 인터페이스에 대하여 (2) (5) | 2025.07.18 |
| [JAVA] 배열의 단점과 ArrayList, LinkedList 비교 (1) (4) | 2025.07.17 |