이번 시간에는 데이터베이스 성능 저하 문제를 해결하기 위한 쿼리 최적화 기법을 학습한다.
실습 대상은 HR 데이터베이스를 사용하는 인사 관리 시스템으로,
최근 직원 수가 5만 명 이상으로 증가하면서 다음과 같은 문제가 발생하고 있다.
- 직원 검색 속도 저하
- 부서·직무별 통계 및 보고서 생성 시간 지연
- 다수의 JOIN과 조건 검색으로 인한 쿼리 성능 악화
해당 시스템은 employees, departments, jobs, locations, job_history 등
여러 테이블이 관계를 맺는 전형적인 실무형 HR 데이터베이스 구조를 가지고 있다.
본 실습에서는 이러한 환경을 바탕으로,
실제 성능 문제가 발생할 수 있는 5개의 쿼리를 순차적으로 분석하고 튜닝하며
EXPLAIN 및 EXPLAIN ANALYZE를 활용한 실행계획 분석 방법을 학습한다.
1. 실행 계획 맛보기 (사번이 100인 사람 검색)
먼저, 실행계획을 확인하는 기본적인 방법부터 알아본다.
실행계획은 데이터베이스가 쿼리를 어떤 순서와 방식으로 처리하는지를 보여주며,
쿼리 성능 분석과 튜닝의 출발점이 된다.
가장 단순한 예제로,
사번(employee_id)이 100인 직원을 조회하는 쿼리는 다음과 같다.
SELECT *
FROM employees
WHERE employee_id = 100;실행계획 확인 쿼리:
EXPLAIN
SELECT *
FROM employees
WHERE employee_id = 100;
실행 결과:

실행 결과를 확인하면 employees_pkey 인덱스를 사용한 Index Scan이 수행된 것을 확인할 수 있다.
이는 employee_id 컬럼이 기본키(Primary Key) 로 정의되어 있으며,
PostgreSQL은 기본키 생성 시 자동으로 인덱스를 생성하기 때문이다.
따라서 해당 쿼리는 테이블 전체를 탐색하는 것이 아니라,
인덱스를 통해 조건에 일치하는 행을 빠르게 조회한다.
이제 실제 쿼리를 수행하는 실제 분석을 해보면 다음과 같다.
실행계획 상세 분석 쿼리:
EXPLAIN ANALYZE
SELECT *
FROM employees
WHERE employee_id = 100;
실행계획 상세 분석 쿼리 결과:

실행계획 상세 분석 결과, 해당 쿼리는 employees 테이블에서 기본키 인덱스(employees_pkey)를 사용한 Index Scan 방식으로 수행되었다.
employee_id를 조건으로 한 단건 조회이기 때문에 인덱스 탐색은 한 번만 발생하였으며, 필요한 데이터는 이미 메모리 버퍼에 존재하여 디스크 I/O 없이 처리되었다.
그 결과 쿼리 전체 실행 시간은 약 0.115ms로 매우 짧게 나타난 것을 확인할 수 있다.
지금까지 실행계획과 실행계획 상세 분석을 통해
쿼리가 데이터베이스에서
어떤 방식으로 처리되는지
를 확인하였다.
이를 바탕으로, 이제
실제 성능 개선을 목표로 한 쿼리 튜닝을 진행한다.
2.이메일 주소가 user1234@corp.com인 사람, lower(email) 사용
먼저, 해당 제목과 같은 상황을 가정하여
인덱스가 없는 컬럼을 조건으로 한 느린 쿼리
를 작성한다.
1. 첫 번째 쿼리 (느린 쿼리)
SELECT *
FROM employees
WHERE lower(email) = 'user1234@corp.com';
실행 계획 상세:

결과를 보면 employees 테이블에 대해 Seq Scan(순차 스캔) 이 발생했고,
필터 조건으로 lower(email) = 'user1234@corp.com'이 적용되어 전체 50,000건을 거의 다 읽은 뒤 조건에 맞지 않는 행을 제거한 것을 확인할 수 있다(Rows Removed by Filter: 50000).
즉, email 컬럼에 함수(lower)를 적용하면서 기존 인덱스가 있더라도 활용하기 어려워졌고, 그 결과 테이블 전체를 탐색하는 방식으로 처리되어 Execution Time이 약 17ms까지 증가했다. 데이터 규모가 더 커지거나 동시 요청이 늘어나면 지연이 더 커질 가능성이 있으므로, 해당 쿼리는 튜닝이 필요해 보인다.
2. 인덱스를 만들어 쿼리 튜닝
lower(email) 조건 조회에서 순차 스캔이 발생하므로, 동일한 조건에서도 인덱스를 사용할 수 있도록 함수 기반 인덱스를 생성하는 방식으로 튜닝할 수 있을 것이다.
CREATE INDEX idx_employees_lower_email
ON employees (lower(email));인덱스 생성 후, 동일 쿼리에 대해 실행계획 상세 분석을 다시 수행하면 다음과 같다.

인덱스 생성 이후 실행계획을 확인한 결과, 기존에 발생하던 Seq Scan 대신
idx_employees_lower_email 인덱스를 사용하는 Bitmap Index Scan 방식으로 실행되었다.
데이터베이스는 먼저 인덱스를 통해 lower(email) 조건에 해당하는 후보 행의 위치를 찾고,
이후 Bitmap Heap Scan을 통해 필요한 데이터만 효율적으로 조회하였다.
그 결과, 전체 테이블을 탐색하던 이전 방식과 달리
불필요한 행을 대부분 제거한 상태에서 데이터 접근이 이루어졌으며,
쿼리의 전체 실행 시간은 약 17ms에서 0.476ms로 크게 감소하였다.
이는 함수 기반 인덱스를 통해 컬럼에 함수가 적용된 조건에서도
인덱스를 활용할 수 있도록 개선한 효과로 볼 수 있다.
3.UNIQUE 함수 인덱스를 적용한 추가 튜닝
앞선 튜닝에서는 lower(email) 조건에서 인덱스를 활용하기 위해 함수 기반 인덱스를 생성하였고, 그 결과 Bitmap Index Scan + Bitmap Heap Scan 방식으로 실행되며 실행 시간이 크게 감소하였다. 다만 이 방식은 플래너 입장에서 조건에 해당하는 행이 여러 건일 가능성을 열어두고, 여러 후보 행의 위치를 모아 한 번에 테이블을 접근하는(Bitmap) 전략을 선택한 것으로 볼 수 있다.
이후 이메일은 원칙적으로 유니크(1명만 존재) 해야 하므로, 대소문자를 무시한 값 기준으로도 유일성이 보장되도록 다음과 같이 UNIQUE 함수 인덱스를 생성하였다.
CREATE UNIQUE INDEX ux_employees_lower_email
ON employees (lower(email));실행 결과:

UNIQUE 인덱스를 적용한 뒤 동일 쿼리를 다시 분석한 결과, 실행계획이 Bitmap Heap Scan 방식에서 Index Scan 방식으로 변경되었다.
즉, 여러 후보를 모아 처리하는 방식이 아니라 인덱스를 통해 대상 행을 바로 단건 탐색하는 실행 전략으로 바뀌면서 불필요한 작업이 줄었고, 실행 시간도 약 0.476ms에서 0.095ms로 추가 감소하였다.
이를 통해 대소문자 무시 이메일 검색에서 성능 개선뿐 아니라, 데이터 정합성(중복 방지)까지 함께 확보할 수 있었다.
4.citext 적용을 통한 추가 튜닝 (최종)
앞선 튜닝에서는 lower(email) 조건을 기준으로 함수 기반 인덱스와 UNIQUE 인덱스를 적용하여, 실행계획을 Bitmap Scan 방식에서 Index Scan 방식으로 개선하고 실행 시간을 크게 단축하였다. 다만 해당 방식은 쿼리 작성 시마다 lower() 함수를 명시적으로 사용해야 하며, 개발자가 이를 누락할 경우 성능 저하가 다시 발생할 수 있는 구조적인 한계가 존재한다.
이를 개선하기 위해 이메일 컬럼을 대소문자 구분 없이 비교가 가능한 citext 타입으로 변경하고, 해당 컬럼에 UNIQUE 제약조건을 적용하였다. 이를 통해 대소문자 무시 이메일 검색을 쿼리 레벨이 아닌 데이터베이스 설계 레벨에서 처리할 수 있도록 개선하였다.
CREATE EXTENSION IF NOT EXISTS citext;
ALTER TABLE employees
ALTER COLUMN email TYPE citext;
ALTER TABLE employees
ADD CONSTRAINT uq_employees_email UNIQUE (email);실행 결과:
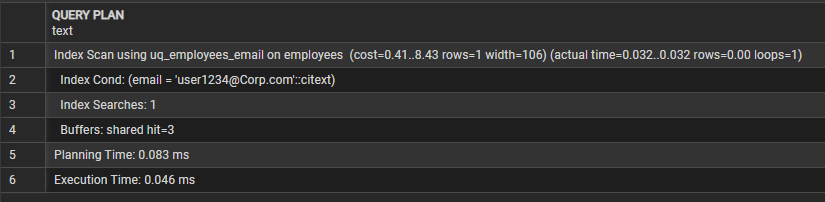
citext 적용 이후 동일한 조건의 조회 쿼리를 실행한 결과, lower() 함수 없이도 대소문자를 무시한 비교가 가능해졌으며, 실행계획은 uq_employees_email 인덱스를 활용한 Index Scan 방식으로 수행되었다. 또한 인덱스 탐색 1회로 바로 단건 조회가 이루어지면서,
전체 실행 시간은 초기 순차 스캔 단계의 약 17.0ms에서 최종적으로 0.046ms까지 감소하여, 본 실습에서 가장 최적화된 결과를 확인할 수 있었다.
3. LIKE 검색 쿼리 작성 후 쿼리 튜닝
(대상: '%gmail.com' 과 같은 접미사(suffix) 검색)
이번에는 이메일 도메인 기준으로 사용자를 찾는 상황을 가정한다. 예를 들어 gmail.com 도메인을 사용하는 직원을 조회하기 위해 접미사 검색을 수행하면, 일반적으로 LIKE 패턴을 사용하게 된다. 먼저 가장 일반적으로 다음과 같은 쿼리를 사용할 수 있다.
1. 가장 느린 쿼리
SELECT *
FROM employees
WHERE email LIKE '%gmail.com';실행 계획 결과:

실행계획을 확인한 결과, 해당 쿼리는 employees 테이블에 대해 Seq Scan(순차 스캔) 방식으로 수행되었다. 이는 email LIKE '%gmail.com' 조건이 문자열 앞부분에 와일드카드(%)를 포함하는 접미사 검색이기 때문에, 일반적인 B-Tree 인덱스를 활용할 수 없기 때문이다. 그 결과 테이블의 전체 데이터를 순차적으로 탐색한 뒤 조건에 맞지 않는 다수의 행이 필터링되었으며(Rows Removed by Filter: 37481), 전체 실행 시간은 약 22.779ms로 비교적 크게 나타났다.
이를 통해 접미사 검색을 단순 LIKE 연산으로 처리할 경우, 데이터 건수가 증가할수록 성능 저하가 발생할 수 있음을 확인하였으며, 해당 쿼리는 추가적인 인덱스 기반 튜닝이 필요한 대상임을 알 수 있다.
2. 도메인 컬럼 분리(email_domain) 기반 인덱스 튜닝
앞선 1번 쿼리(email LIKE '%gmail.com')는 문자열 앞부분에 와일드카드(%)가 포함된 접미사 검색이기 때문에, 일반적인 B-Tree 인덱스를 활용할 수 없어 Seq Scan이 발생하였다. 이 방식은 테이블 전체를 순차 탐색한 뒤 조건에 맞지 않는 행을 필터링하는 구조이며, 데이터 건수가 증가할수록 성능 저하가 커질 수 있는 한계가 있다.
이를 근본적으로 개선하기 위해, 이메일에서 도메인 부분을 별도 컬럼으로 분리하여 패턴 검색(LIKE) 을 정확한 값 비교(=) 로 변경하였다. 즉, “문자열에서 특정 접미사를 찾는 문제”를 “도메인 값이 같은지 확인하는 문제”로 바꾸어, PostgreSQL이 B-Tree 인덱스를 안정적으로 활용할 수 있는 구조로 설계를 개선하였다.
구체적으로 email_domain 컬럼을 생성 컬럼(Stored Generated Column)으로 추가하여, 이메일 변경 시에도 도메인이 자동으로 계산·저장되도록 하였고, 해당 컬럼에 B-Tree 인덱스를 생성하였다. 이로 인해 도메인 검색 시 실행계획이 Seq Scan에서 Index Scan으로 변경되었으며, 실제 실행 시간 또한 유의미하게 감소하였다.
적용:
ALTER TABLE employees
ADD COLUMN email_domain text
GENERATED ALWAYS AS (split_part(email, '@', 2)) STORED;
CREATE INDEX idx_employees_email_domain
ON employees (email_domain);
--- email_domain 컬럼 생성튜닝 쿼리:
SELECT employee_id, first_name, last_name, email, department_id, job_id, status
FROM employees
WHERE email_domain = 'gmail.com';
분석결과:

email_domain = 'gmail.com' 조건에 대해 Bitmap Index Scan + Bitmap Heap Scan이 사용되었다.
이는 이메일 도메인을 별도 컬럼으로 분리함으로써 문자열 접미사 검색(LIKE)을 정확한 값 비교(=) 로 변경할 수 있었고, 그 결과 인덱스를 통해 대상 행만 선별적으로 접근할 수 있게 되었기 때문이다.
실행계획 상 전체 테이블을 순차적으로 탐색하던 방식(Seq Scan)이 제거되었으며, 실제 실행 시간은 2.769ms로 이전 접미사 LIKE 쿼리 대비 유의미하게 감소하였다.
이를 통해 패턴 검색을 유지하는 튜닝보다, 쿼리 조건을 인덱스 친화적인 형태로 구조적으로 개선하는 것이 성능 향상에 더 효과적임을 확인하였다.
4. 정렬(ORDER BY)과 필터가 결합된 쿼리 작성 후 쿼리 튜닝
(대상: hire_date >= CURRENT_DATE - INTERVAL '365 days’ 이면서 재직중인 사람을 연봉순으로 상위 100명만 출력)
1. 가장 느린 쿼리
일반적으로 우리는 다음 대상에 대한 퀴리를 다음과 같이 나타낼 수 있다.
SELECT *
FROM employees
WHERE
hire_date >= CURRENT_DATE - INTERVAL '365 days'
AND status = 'ACTIVE'
ORDER BY salary DESC
LIMIT 100;
분석 결과:

해당 쿼리는 employees 테이블에 대해 Seq Scan이 수행되었다.
이는 hire_date와 status 조건을 동시에 만족하면서 salary DESC 정렬까지 처리할 수 있는 인덱스가 존재하지 않기 때문이다.
실행계획을 보면, 전체 50,000건의 데이터를 순차적으로 스캔한 뒤 조건에 맞지 않는 모든 행이 필터링되었으며
(Rows Removed by Filter: 50000), 이후 남은 결과에 대해 정렬(Sort) 을 수행한 후 상위 100건을 제한(Limit)하는 구조이다.
즉, 조건 필터링 → 전체 정렬 → LIMIT 이 순서로 처리되어,
실제로 반환되는 행이 없더라도 테이블 전체 스캔과 정렬 비용이 모두 발생하였다.
그 결과 실행 시간은 약 8.8ms로 측정되었으며, 이는 인덱스를 활용하지 못한 전형적인 느린 쿼리 패턴임을 보여준다.
2. 복합 인덱스 적용을 통한 정렬 제거 튜닝
앞선 실행계획에서는 employees 테이블 전체에 대해 Seq Scan → Sort → Limit 이 수행되었다.
이는 WHERE 조건(hire_date, status)과 ORDER BY salary DESC를 동시에 만족하는 인덱스가 존재하지 않았기 때문이다.
그 결과 조건에 맞는 데이터가 없더라도 전체 테이블 스캔과 정렬 비용이 모두 발생하였다.
이를 개선하기 위해, 필터 조건과 정렬 조건을 함께 포함하는 복합 인덱스를 생성하여
PostgreSQL이 정렬(Sort) 단계 없이 인덱스 순서대로 상위 데이터만 읽을 수 있도록 튜닝하였다.
복합 인덱스 생성:
CREATE INDEX idx_employees_active_hire_salary
ON employees (status, hire_date, salary DESC);- status, hire_date : WHERE 조건 처리
- salary DESC : ORDER BY 정렬 제거
- 인덱스 순서 자체가 “연봉 내림차순”이므로 추가 정렬 불필요
쿼리 재실행 후 분석 결과:

복합 인덱스(idx_employees_active_hire_salary) 적용 후 실행계획을 확인한 결과,
기존의 Seq Scan은 제거되고 Index Scan이 사용되었다.
이를 통해 조건(status, hire_date)에 맞는 데이터만 인덱스에서 직접 탐색할 수 있게 되었으며,
전체 테이블을 순차적으로 탐색하는 비용이 제거되었다.
다만 실행계획 상 Sort 노드가 여전히 존재하는데, 이는 조건에 해당하는 결과가 존재하지 않아
정렬 대상 데이터가 없더라도 실행계획 구조상 Sort 단계가 포함되었기 때문이다.
실제 정렬 비용은 매우 작으며, 전체 실행 시간은 0.045ms로 이전 실행 대비 크게 감소하였다.
이를 통해 WHERE 조건과 ORDER BY를 동시에 만족하는 복합 인덱스를 적용함으로써
테이블 전체 스캔과 대규모 정렬 비용을 제거할 수 있었고,
LIMIT과 결합된 상위 N건 조회 성능이 효과적으로 개선되었음을 확인하였다.
최종 튜닝 결과: 8.798ms → 0.045ms
5. OR 조건 쿼리 작성 후 쿼리 튜닝
(조건 : 부서코드가 10 또는 직무가 3, 4, 5 안에 있는 사람 검색)
일반적으로 조건에 맞는 쿼리는 다음과 같이 작성할 수 있다.
1. 가장 느린 쿼리
SELECT *
FROM employees
WHERE department_id = 10
OR job_id IN (3, 4, 5);
분석 결과:

실행계획을 확인한 결과, 해당 쿼리는 employees 테이블에 대해 Seq Scan(순차 스캔) 방식으로 수행되었다. 이는 department_id = 10 OR job_id IN (3, 4, 5) 조건이 서로 다른 컬럼에 대한 OR 조건으로 구성되어 있어, 개별 인덱스가 존재하더라도 PostgreSQL이 이를 효율적으로 결합하여 활용하기 어렵기 때문이다.
그 결과 테이블의 전체 데이터를 순차적으로 탐색한 뒤 조건에 맞지 않는 다수의 행이 필터링되었으며, 인덱스를 활용한 탐색이 이루어지지 않아 비교적 큰 실행 시간(7.206ms)이 소요되었다
.
2. 인덱스 생성 후 OR 조건 쿼리 튜닝
앞선 1번 쿼리는 department_id = 10 OR job_id IN (3, 4, 5) 형태의 OR 조건으로 인해 employees 테이블에 대해 Seq Scan이 발생하였다. 이는 서로 다른 컬럼에 대한 OR 조건을 효율적으로 처리할 수 있는 인덱스가 존재하지 않았기 때문이다.
이를 개선하기 위해, OR 조건에 사용되는 컬럼(department_id, job_id)에 대해 개별 인덱스를 생성하고, 조건을 UNION ALL로 분해하였다. 이 방식은 각 SELECT 문이 자신에게 맞는 인덱스를 사용할 수 있도록 하여, 전체 테이블을 순차 탐색하는 대신 조건에 해당하는 데이터만 선택적으로 접근할 수 있게 한다.
그 결과 기존의 Seq Scan 기반 실행계획이 제거되고, 불필요한 전체 스캔과 대량 필터링 비용이 줄어들어 OR 조건을 단일 쿼리로 처리할 때보다 더 효율적인 실행계획을 유도할 수 있다.
인덱스 생성:
CREATE INDEX idx_employees_department_id ON employees (department_id);
CREATE INDEX idx_employees_job_id ON employees (job_id);
튜닝 쿼리 (OR 조건 분해)
SELECT *
FROM employees
WHERE department_id = 10
UNION ALL
SELECT *
FROM employees
WHERE job_id IN (3, 4, 5)
AND department_id <> 10;
분석 결과:

실행계획을 확인한 결과, job_id IN (3, 4, 5) 조건에 대해 Bitmap Index Scan이 사용되었고, 이후 Bitmap Heap Scan을 통해 실제 데이터가 조회되었다. 이는 job_id 컬럼에 생성된 인덱스를 활용하여 조건을 만족하는 행의 위치를 먼저 선별한 뒤, 필요한 테이블 블록만 접근하는 방식이다.
이 과정에서 department_id <> 10 조건은 인덱스 단계가 아닌 Heap 단계에서 추가로 필터링되었으며, 필터링으로 제거된 행 수는 매우 적어(Rows Removed by Filter: 20) 전체 성능에 큰 영향을 주지 않았다. 결과적으로 전체 테이블을 순차 탐색하던 기존 방식과 달리, 조건에 해당하는 데이터만 선택적으로 접근함으로써 실행 시간이 1.880ms로 크게 감소하였다.
이를 통해 OR 조건 분해 후 인덱스를 적용하면, PostgreSQL이 Bitmap Scan 기반 실행계획을 선택하여 불필요한 전체 스캔을 제거하고 보다 효율적인 쿼리 수행이 가능함을 확인하였다.
3. Partial Index 및 BitmapOr 기반 OR 조건 최종 튜닝
앞선 2번 튜닝에서는 department_id와 job_id 컬럼에 대한 인덱스를 생성하고,
OR 조건을 UNION ALL로 분해함으로써 실행계획을 Seq Scan에서
Bitmap Index Scan + Bitmap Heap Scan 방식으로 개선하였다.
이를 통해 전체 테이블을 순차 탐색하는 비용은 제거되었으나,
여전히 조건 범위가 넓어 Heap 접근 비용이 발생하는 구조였다.
이를 추가로 개선하기 위해, OR 조건에 정확히 부합하는 데이터만 포함하도록
Partial Index를 생성하여 인덱스 탐색 범위를 더욱 축소하였다.
이 방식은 불필요한 인덱스 엔트리를 제거함으로써,
PostgreSQL이 각 조건에 대해 더 작은 인덱스를 사용해
후보 행을 빠르게 선별할 수 있도록 한다.
인덱스 생성:
CREATE INDEX idx_emp_dept10
ON employees (employee_id)
WHERE department_id = 10;
CREATE INDEX idx_emp_job345
ON employees (employee_id)
WHERE job_id IN (3, 4, 5);
실행 결과 분석

실행계획을 확인한 결과, PostgreSQL은
각 Partial Index에 대해 Bitmap Index Scan을 수행한 뒤,
이를 BitmapOr로 결합하여 Bitmap Heap Scan 방식으로 데이터를 조회하였다.
이를 통해 OR 조건을 단일 쿼리로 유지하면서도,
각 조건을 개별 인덱스로 효율적으로 처리할 수 있었다.
그 결과 실행 시간은 1.407ms로 측정되어,
2번 튜닝 대비 Heap 접근 비용이 추가로 감소하였고,
OR 조건 쿼리에 대해 가장 효율적인 실행계획을 확인할 수 있었다.
최종적으로 7.206ms →1.407ms로 개선된 것을 볼 수 있다.
마무리하며:
이번 실습에서는 HR 데이터베이스 환경을 기반으로,
데이터 증가로 인해 발생할 수 있는 대표적인 쿼리 성능 저하 사례 5가지를 단계적으로 분석하고 튜닝하였다.
각 단계마다 EXPLAIN 및 EXPLAIN ANALYZE를 활용하여 실행계획을 직접 확인하고,
왜 느린지 → 어떻게 개선할 수 있는지 → 실제로 얼마나 개선되었는지를 수치와 실행계획으로 검증하였다.
특히 단순히 인덱스를 추가하는 수준을 넘어,
- 함수 사용으로 인한 인덱스 미사용 문제
- 접미사 LIKE 검색의 구조적 한계
- ORDER BY와 LIMIT이 결합된 쿼리의 정렬 비용 문제
- OR 조건에서 발생하는 Seq Scan 문제
등 실무에서 자주 발생하는 성능 이슈를 실제 데이터 기준으로 재현하고,
함수 기반 인덱스, citext, 컬럼 분리, 복합 인덱스, Partial Index, BitmapOr 등
PostgreSQL이 제공하는 다양한 인덱스 및 실행 전략을 상황에 맞게 적용하였다.
이를 통해 쿼리 튜닝은 단순히 “인덱스를 추가하는 작업”이 아니라,
쿼리 조건의 특성, 데이터 분포, 실행계획을 종합적으로 고려하여 가장 적절한 접근 방식을 선택하는 과정임을 확인하였다. 본 실습은 향후 실제 서비스 환경에서 성능 문제를 분석하고 개선하는 데 있어 실질적인 기준과 접근 방법을 제공할 수 있을 것이다.
'최적화' 카테고리의 다른 글
| [최적화] 수강신청 메인 페이지 성능 개선 (N+1, Redis) (0) | 2025.10.15 |
|---|